浅析基本排序算法
2023/08/16
基本排序算法谱系
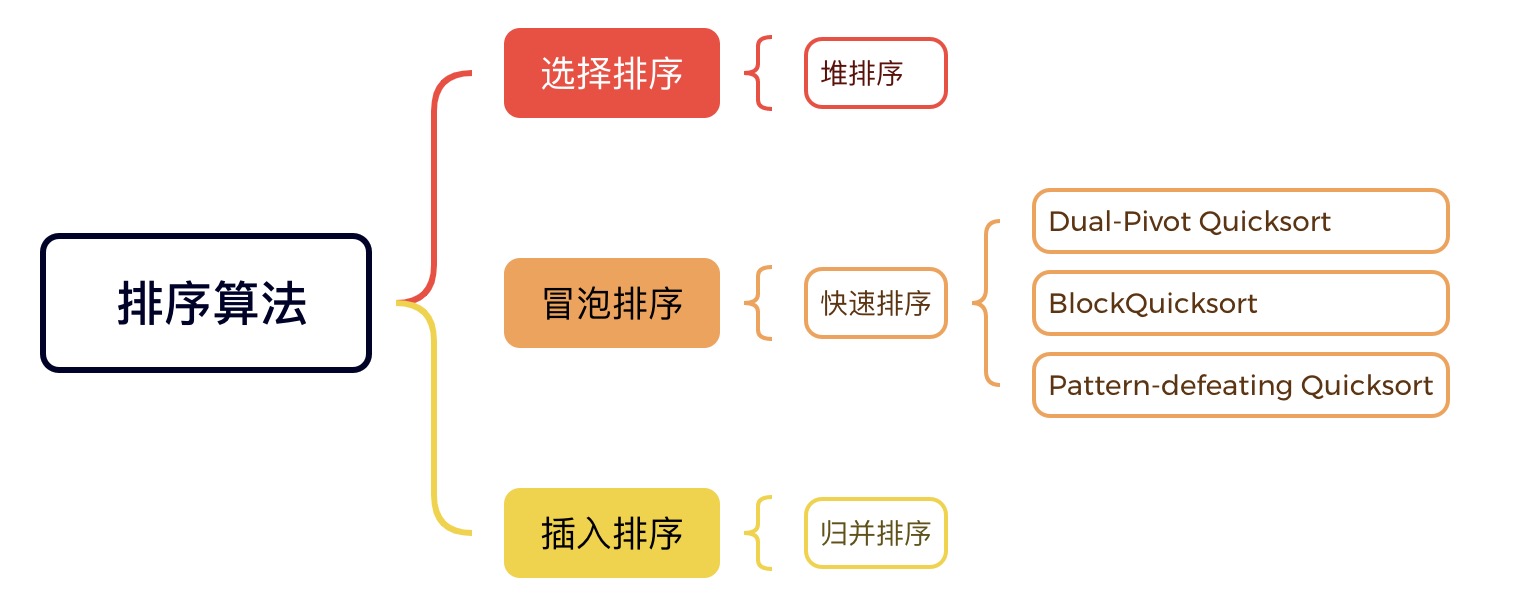
对于排序算法来说,最耗时有两部分:比较和交换。这也是排序算法的核心步骤。
朴素排序算法
冒泡排序(Bubble Sort)
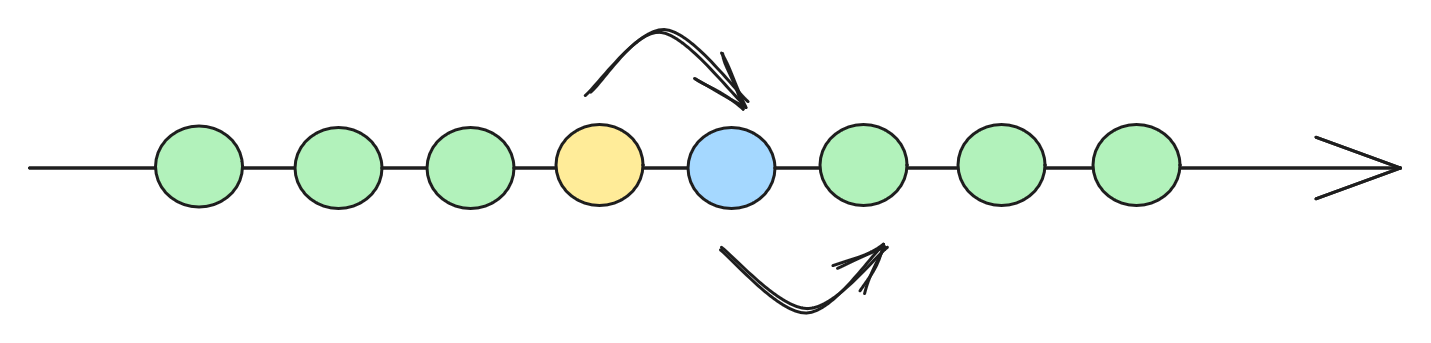
冒泡排序比较原始,不断调整相邻元素的顺序来排序。算法得名于,大的元素会经过交换,慢慢像泡泡一样“浮”到数列的顶端。 冒泡排序的比较和移动操作,都很多,是很慢的排序算法。
C++ 冒泡排序:
#include <iostream>
using namespace std;
template<typename T>
void bubble_sort(T arr[], int len) {
int i, j;
for (i = 0; i < len - 1; i++) {
for (j = 0; j < len - 1; j++) {
if (arr[j] > arr[j + 1]) {
swap(arr[j], arr[j + 1]);
}
}
}
}
int main(int argc, const char * argv[]) {
int arr[] = {19, 93, 3, 25};
int len = (int) sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
for (int i = 0; i < len; i++) {
cout << arr[i] << ' ';
}
cout << endl;
return 0;
}
选择排序(Selection Sort)

选择排序就是不断选出,剩下元素中的最值,来实现排序。选择排序的数据移动是精准操作,比冒泡排序好。
C++ 选择排序:
#include <iostream>
using namespace std;
template<typename T>
void selection_sort(T arr[], int len) {
int i, j;
for (i = 0; i < len - 1; i++) {
int min = i;
for (j = i; j < len - 1; j++) {
if (arr[j] < arr[min]) {
min = j;
}
}
if (min != i) {
swap(arr[min], arr[i]);
}
}
}
int main(int argc, const char * argv[]) {
int arr[] = {19, 93, 3, 25};
int len = (int) sizeof(arr) / sizeof(*arr);
selection_sort(arr, len);
for (int i = 0; i < len; i++) {
cout << arr[i] << ' ';
}
cout << endl;
return 0;
}
插入排序(Insertion Sort)
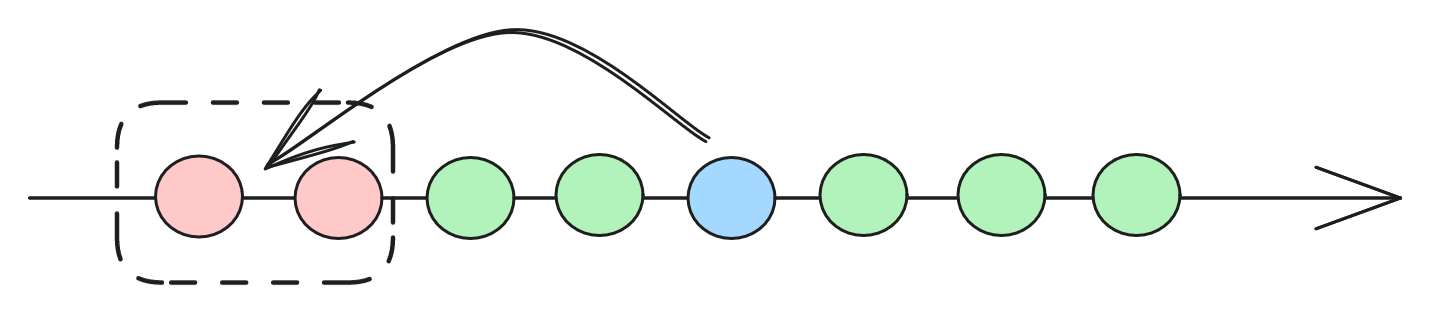
新元素在已排序的列里,找到合适的位置插入。插入的位置,可以通过二分查找优化,插入排序的比较次数,远小于冒泡排序和选择排序。数据移动次数,也占优。不过顺序数据移动的开销,远不及比较操作。朴素排序算法中,插入排序,一般最快。
C++ 插入排序:
#include <iostream>
using namespace std;
template<typename T>
void insertion_sort(T arr[], int len) {
int i, j;
T key;
// 从1开始,因为下标0默认是有序列的开始
for (i = 1; i < len; i++) {
// 记录要插入的元素
key = arr[i];
// 从已经排序的最右边开始比较,找到比其小的元素
j = i;
while (j > 0 && key < arr[j - 1]) {
arr[j] = arr[j - 1];
j--;
}
// 存在比其小的元素,插入
if (j != i) {
arr[j] = key;
}
}
}
int main(int argc, const char * argv[]) {
int arr[] = {19, 93, 3, 25};
int len = (int) sizeof(arr) / sizeof(*arr);
insertion_sort(arr, len);
for (int i = 0; i < len; i++) {
cout << arr[i] << ' ';
}
cout << endl;
return 0;
}
折半插入排序
插入排序还可以通过二分查找算法优化性能。但基本思想和插入排序一样,仅对时间复杂度中的常数优化。
void insertion_sort(int arr[], int len) {
if (len < 2) return;
for (int i = 1; i != len; i++) {
int key = arr[i];
// 指定范围内查找大于目标值的第一个元素
auto index = upper_bound(arr, arr + i, key) - arr;
// 使用 memmove 移动元素,比使用 for 循环速度更快,时间复杂度仍为 O(n)
memmove(arr + index + 1, arr + index, (i - index) * sizeof(int));
arr[index] = key;
}
}
《STL源码剖析》中插入排序实现
stl_algo.h:
__VALUE_TYPE实现:
#ifndef LEARNING_STL_STL_ALGO_H
#define LEARNING_STL_STL_ALGO_H
// __VALUE_TYPE 实现,及其依赖
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
template <class _Iterator>
struct iterator_traits {
typedef typename _Iterator::iterator_category iterator_category;
typedef typename _Iterator::value_type value_type;
typedef typename _Iterator::difference_type difference_type;
typedef typename _Iterator::pointer pointer;
typedef typename _Iterator::reference reference;
};
template <class _Tp>
struct iterator_traits<_Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef _Tp& reference;
};
template <class _Tp>
struct iterator_traits<const _Tp*> {
typedef random_access_iterator_tag iterator_category;
typedef _Tp value_type;
typedef ptrdiff_t difference_type;
typedef const _Tp* pointer;
typedef const _Tp& reference;
};
template <class _Iter>
inline typename iterator_traits<_Iter>::iterator_category
__iterator_category(const _Iter&)
{
typedef typename iterator_traits<_Iter>::iterator_category _Category;
return _Category();
}
template <class _Iter>
inline typename iterator_traits<_Iter>::difference_type*
__distance_type(const _Iter&)
{
return static_cast<typename iterator_traits<_Iter>::difference_type*>(0);
}
template <class _Iter>
inline typename iterator_traits<_Iter>::value_type*
__value_type(const _Iter&)
{
return static_cast<typename iterator_traits<_Iter>::value_type*>(0);
}
template <class _Iter>
inline typename iterator_traits<_Iter>::iterator_category
iterator_category(const _Iter& __i) { return __iterator_category(__i); }
template <class _Iter>
inline typename iterator_traits<_Iter>::difference_type*
distance_type(const _Iter& __i) { return __distance_type(__i); }
template <class _Iter>
inline typename iterator_traits<_Iter>::value_type*
value_type(const _Iter& __i) { return __value_type(__i); }
#define __VALUE_TYPE(__i) __value_type(__i)
插入排序:
// 插入排序
template <class RandomAccessIterator, class T>
void __unguarded_linear_insert(RandomAccessIterator last, T value) {
RandomAccessIterator next = last;
--next;
// insertion sort 内循环
// 注意,一旦不再出现逆转对(inversion),循环就可以结束了
while(value < *next) { // 逆转对(inversion)存在
*last = *next; // 调整
last = next; // 调整迭代器
--next; // 左移一个位置
}
*last = value; // value 的正确落脚处
}
template <class RandomAccessIterator, class T>
inline void __linear_insert(RandomAccessIterator first,
RandomAccessIterator last, T*) {
T value = *last; // 记录尾元素
if (value < *first) { // 尾比头还小(注意,头端必为最小元素)
// 比最小元素还小,不需要一个个比较,直接一次处理
std::copy_backward(first, last, last + 1); // 将整个区间向右移一个位置
*first = value; // 令头元素等于原先的尾元素值
}
else // 尾不小于头
__unguarded_linear_insert(last, value);
}
// 插入排序
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first,
RandomAccessIterator last) {
if (first == last) return;
for (RandomAccessIterator i = first + 1; i != last; ++i) // 外循环
__linear_insert(first, i, __VALUE_TYPE(first)); // 以上,[first, i) 形成一个子区间
}
#endif //LEARNING_STL_STL_ALGO_H
测试main.cpp:
#include <iostream>
#include "stl_algo.h"
int main() {
int arr[] = {19, 93, 3, 25};
int len = (int) sizeof(arr) / sizeof(*arr);
__insertion_sort(arr, &arr[len]);
for (int i = 0; i < len; i++) {
std::cout << arr[i] << ' ';
}
std::cout << std::endl;
return 0;
}
之所以用unguarded_前缀命名,是因为,一般的insertion sort在内循环,需要判断是否相邻元素是“逆转对”,同时还要判断循环是否越界,需要两次判断。
但__unguarded_linear_insert是在__linear_insert中调用,最小值一定在内循环区间中,就可以省略一个判断。虽然可能无足轻重,但大量数据情况下,影响可观。STL中以__unguraded前缀命名者,即边界条件的检验可以省略,或说已经融入特定条件。
插入排序的复杂度为O(N^2),并不理想,但数据量少的时候,有不错的效果,原因是一些实现上的技巧,使得他不想其他排序算法,有诸如递归调用等操作,带来的额外负荷。
高级排序算法
快速排序(Quick Sort)
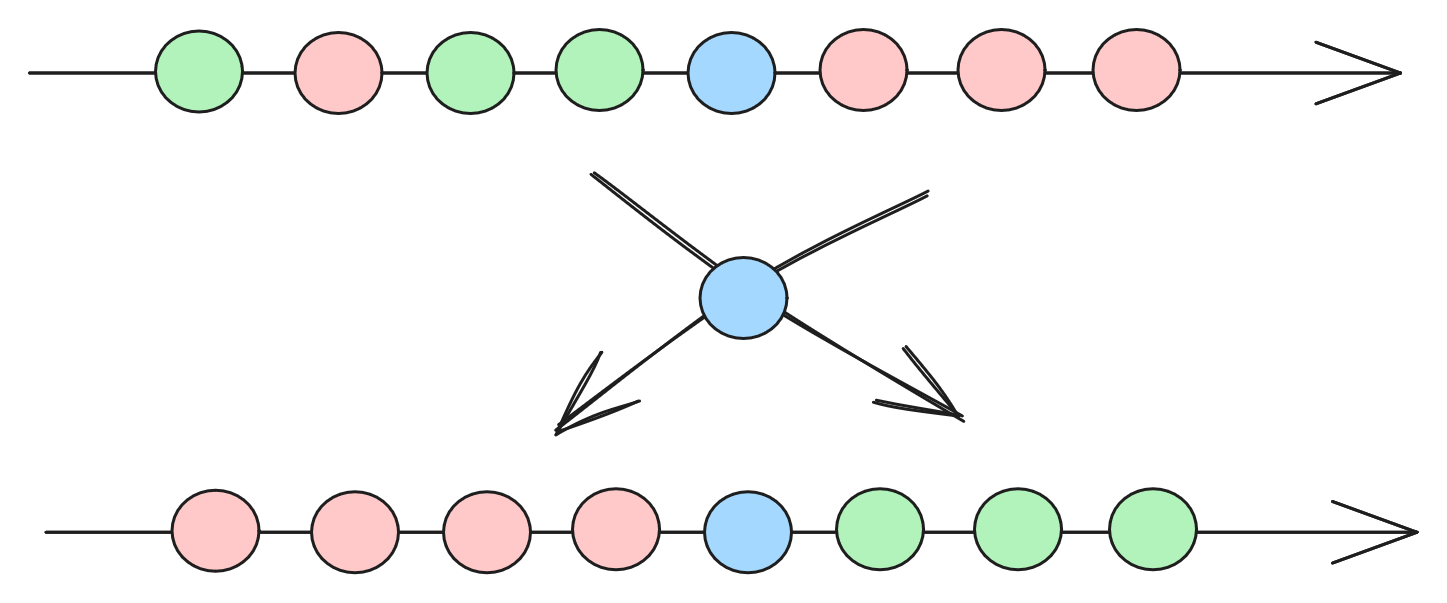
快速排序可以理解为一种批量的冒泡排序。每一个元素的浮沉,不再取决于相邻元素的比较,而是取决于中枢元素的比较,且每次沉浮不再是一个身位,而是直接到达上下半区。快速排序通常很快。
stl_algo.h:
#ifndef LEARNING_STL_STL_ALGO_H
#define LEARNING_STL_STL_ALGO_H
// 快排
const int __stl_threshold = 16;
// 返回a,b,c之居中者
template<class T>
inline const T& __median(const T& a, const T& b, const T& c) {
if (a < b) {
if (b < c) { // a < b < c
return b;
} else if (a < c) { // a < c < b
return c;
} else { // c < a < b
return a;
}
} else if ( a < c) { // b < a < c
return a;
} else if ( b < c) { // b < c < a
return c;
} else { // c < b < a
return b;
}
}
// 分割函数,返回值为分割以后,右段第一个位置
template <class RandomAccessIterator, class T>
RandomAccessIterator __unguarded_partition(RandomAccessIterator first,
RandomAccessIterator last,
T pivot) {
while (true) {
while (*first < pivot) ++first; // first 找到 >= pivot 的元素就停下来
--last;
while(pivot < *last) --last; // last 找到 <= pivot 的元素就停下来
if (!(first < last)) {
return first; // 交错,结束循环
}
std::iter_swap(first, last); // 大小值,交换
++first;
}
}
template <class RandomAccessIterator>
inline void __quick_sort_loop(RandomAccessIterator first,
RandomAccessIterator last);
template <class RandomAccessIterator, class T>
inline void __quick_sort_loop_aux(RandomAccessIterator first,
RandomAccessIterator last,
T*) {
while (last - first > __stl_threshold) {
// median-of-3 partitioning
RandomAccessIterator cut = __unguarded_partition(first, last,
T(__median(*first, *(first + (last - first)/2),
*(last - 1))));
if (cut - first >= last - cut) {
__quick_sort_loop(cut, last); // 对右段递归处理
last = cut;
} else {
__quick_sort_loop(first, cut); // 对左段递归处理
first = cut;
}
}
}
template <class RandomAccessIterator>
inline void __quick_sort_loop(RandomAccessIterator first,
RandomAccessIterator last) {
__quick_sort_loop_aux(first, last, __VALUE_TYPE(first));
}
// 具体实现,见上文的插入排序
template <class RandomAccessIterator>
inline void __final_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last) {
__insertion_sort(first, last);
}
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first,
RandomAccessIterator last) {
if (!(first == last)) {
__quick_sort_loop(first, last);
__final_insertion_sort(first, last);
}
}
#endif //LEARNING_STL_STL_ALGO_H
测试main.cpp:
#include <iostream>
#include "stl_algo.h"
int main() {
int arr[] = {19, 93, 3, 25, 89, 6, 26};
int len = (int) sizeof(arr) / sizeof(*arr);
sort(arr, &arr[len]);
for (int i = 0; i < len; i++) {
std::cout << arr[i] << ' ';
}
std::cout << std::endl;
return 0;
}
阈值(threshold)
数据量少的时候,如十来个元素,Quick Sort不一定比 Insertion Sort 快,Qick Sort即使极小的子序列,也有很多函数递归调用。
所以需要适当评估序列的大小,决定使用Quick Sort还是Insertion Sort。多少大小呢?因设备而异,5~20都有可能。
几近排序(final insertion sort)
如果序列是快完成了,但尚未完成的状态,用Insertion Sort处理这些子序列,效率一般也比Quick Sort要好,Quick Sort可能会“将所有子序列彻底排序”。
堆排序(Heap Sort)
堆排序是选择排序的一种改进,使用堆结构来优化选择过程。
但堆结构需要两次比较,和一次数据移动,更糟糕的是数据访问存在跳跃。正式多一倍的比较次数,和不规则的访问,使得堆排序在高级排序算法中垫底,通常不及快排四成。
具体实现,见浅析基本数据结构:堆 heap
堆排序的重要地位
堆排序是当前所知,唯一能够同时最优利用空间和时间的方法,且在最坏的情况下,他也能保证使用~2NlogN次比较和恒定的额外空间。SGI(Silicon Graphics Computer Systems, Inc.)版本的STL的排序算法,在快速排序的分割行为,有恶化为二次行为的倾向是,会改用堆排序(Heap Sort)
堆实现的优先队列,在应用中也很重要,他能在插入操作和删除最大元素操作混合的,动态场景中,能保证对数级别的运行时间。
当空间十分紧张的时候,他很优秀,如嵌入式系统。但现代计算机很少使用,主要缺点是他无法利用缓存。数据元素很少和相邻元素比较,缓存命中次数远远低于其他比较在相邻元素进行的算法,如快速排序,归并排序,甚至希尔排序。
归并排序(Merge Sort)
归并排序可以看成,是批量的插入排序。由于插入本身是有序的,数据可以一步移动到位,很高效。其复杂度也为O(NlogN),但由于需要额外内存,内存之间移动数据消耗不少,效率比如快速排序。概念简单,实现简单,是归并排序的优点。
但是,快排每轮操作只需要移动一半多的元素,元素有一部分不需要移动,因这半步之差,归并排序性能逊于快排。
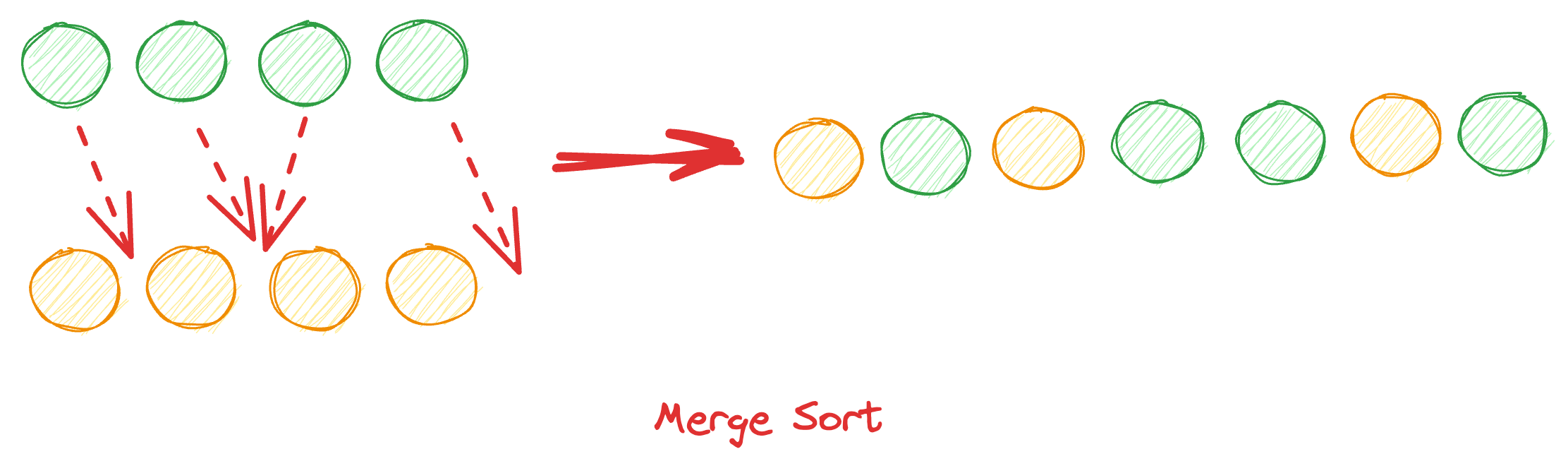
实现merge
将两个已排序的列表,合并起来,并放到另一个空间。所得结果,也是有序的序列i。这是一种稳定(stable)操作,每个作为数据来源的子序列中,元素相对次序不会变动。注意:这里的实现需要额外的空间
merge算法:
// merge
template <class InputIterator1, class InputIterator2, class OutputIterator>
OutputIterator merge(InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result) {
while(first1 != last1 && first2 != last2) { // 两个序列都尚未完成
if (*first2 < *first1) { // 序列2的元素小
*result = *first2; // 登记序列2元素
++first2; // 序列2前进1
} else {
*result = *first1; // 序列1的元素更小
++first1; // 序列1前进1
}
++result;
}
// 最后剩余元素,以 copy 复制到目的端,以下序列一定至少有一个为空
return std::copy(first2, last2, std::copy(first1, last1, result));
}
merge_backward实现:
template<class BidirectionalIter1,
class BidirectionalIter2,
class BidirectionalIter3>
BidirectionalIter3 merge_backward(BidirectionalIter1 first1,
BidirectionalIter1 last1,
BidirectionalIter2 first2,
BidirectionalIter2 last2,
BidirectionalIter3 result) {
if (first1 == last1)
return std::copy_backward(first2, last2, result);
if (first2 == last2)
return std::copy_backward(first1, last1, result);
--last1;
--last2;
while (true) {
if (*last2 < *last1) {
*--result = *last1;
if (first1 == last1)
return std::copy_backward(first2, ++last2, result);
--last1;
} else {
*--result = *last2;
if (first2 == last2)
return std::copy_backward(first1, ++last1, result);
--last2;
}
}
}
inplace_merge(应用于有序区间)
如果两个需要连接在一起的序列:[first, middle)和[middle, last),都已经排序。inplace_merge 就可以合并二者,且保持有序。和merge一样,也是稳定操作,作为数据源子序列中的元素,相对次序不会变动。
inplace_merge:
// 缓冲区有效情况下的辅助函数
template<class BidirectionalIterator, class Distance, class Pointer>
void __merge_adaptive(BidirectionalIterator first,
BidirectionalIterator middle,
BidirectionalIterator last,
Distance len1, Distance len2,
Pointer buffer, Distance buffer_size) {
if (len1 <= len2 && len1 <= buffer_size) { // case1. 缓冲区足够安置序列1
Pointer end_buffer = std::copy(first, middle, buffer);
merge(buffer, end_buffer, middle, last, first);
} else { // case2. 缓冲区足够安置序列2
Pointer end_buffer = std::copy(first, middle, buffer);
merge_backward(first, middle, buffer, end_buffer, last);
}
// TODO case3. 缓冲区不足安置任何一个序列
}
// 辅助函数
template<class BidirectionalIterator, class T, class Distance>
inline void __inplace_merge_aux(BidirectionalIterator first,
BidirectionalIterator middle,
BidirectionalIterator last,
T *, Distance *) {
Distance len1 = 0;
distance(first, middle, len1); // len1 表示序列一的长度
Distance len2 = 0;
distance(middle, last, len2); // len2 表示序列二的长度
// 暂存缓冲区
temporary_buffer<BidirectionalIterator, T> buf(first, last);
if (buf.begin() == 0) {
// 内存配置失败,需要使用不借助缓冲区的算法,此处省略
} else {
// 有缓冲区的情况下
__merge_adaptive(first, middle, last, len1, len2, buf.begin(), Distance(buf.size()));
}
}
template<class BidirectionalIterator>
inline void inplace_merge(BidirectionalIterator first,
BidirectionalIterator middle,
BidirectionalIterator last) {
// 只有有任意序列为空,则什么都不做
if (first == middle || middle == last) return;
__inplace_merge_aux(first, middle, last, value_type(first), distance_type(first));
}
归并排序(Merge Sort)实现
既然将两个有序区间归并为一个有序区间,效果不错。我们就可以用分而治之的办法,以各个击破的方式,对每一个区间排序。
首先,将区间对半分割,左右各自排序,再利用 inplace_merge 重新组合为一个完整的有序序列。
其中对半分割操作可以递归执行,直到每一小段长度为0或1(那么这一小段,也就自动完成了排序)。归并排序的复杂度为O(NlogN),和快速排序一样,但是由于归并排序需要借用额外的内存,内存之间的移动(复制)数据会消耗不少时间。
归并排序实现简单,概念简单,是其优点。
归并排序(merge sort):
// 归并排序(merge sort)
template<class BidirectionalIterator>
void mergesort(BidirectionalIterator first, BidirectionalIterator last) {
typename iterator_traits<BidirectionalIterator>::difference_type n = distance(first, last);
if (n == 0 || n == 1) {
return;
} else {
BidirectionalIterator mid = first + ( n / 2);
mergesort(first, mid);
mergesort(mid, last);
SGI::inplace_merge(first, mid, last);
}
}
常见工业排序算法
Dual-Pivot Quicksort(双枢三分快排)
2009年问世的改进版本的快速排序,从Java7开始被其标准库所采用。与经典快排主要不同是,引入了两个中枢点,将序列分为三段:
- 三分递归深度,只有二分的63%左右;
- 三分操作比二分操作复杂,三分快排的比较次数和数据移动次数,均多于经典快排,为什么比经典的快呢?主要是三分更擅长利用cache。现代计算机的数据操作最慢的过程是首次读入,而读入后,短时间内进行多次访问,数据有cache,开销会小些。由1的分析,三分比二分减少了冷数据访问。而操作的复杂度,都是在热数据上,所以更快,特别是内存敏感性语言实现的(如Java和Go)。
阅读资料
log
- 2023/08/16 初稿
- 2023/08/28 补充堆排序描述
- 2023/09/02 归并排序初稿